
Cléber da Costa Figueiredo
Boa parte das fake news, em torno das pesquisas de opinião de voto, são construídas em torno do tamanho da amostra dessas pesquisas.
Parte do eleitorado não consegue entender como tão poucas pessoas podem representar todos os eleitores brasileiros.
A questão é que o cálculo do tamanho da amostra da proporção de eleitores não é linear. Isso não é uma tarefa simples para se explicar para a população que, mesmo com alfabetização elevada, não entente a não linearidade do tamanho das amostras das pesquisas de intenção de voto, pois convive diariamente rodeada de cenários lineares.
O que a população vê no dia a dia é que quanto mais tempo os membros da família passam no banho, mais alto o valor pago da conta de luz; quanto mais se lava a calçada, maior o gasto de água; quanto mais se utiliza o carro, maior é o consumo de combustível.
E por aí vai.
Com o tamanho da amostra de uma pesquisa de intenção de voto o cenário é diferente. A partir de uma determinada população de eleitores, o tamanho da amostra converge para um valor. Funciona como uma linha de resistência, a partir da qual, o tamanho da amostra não terá como ultrapassá-la.
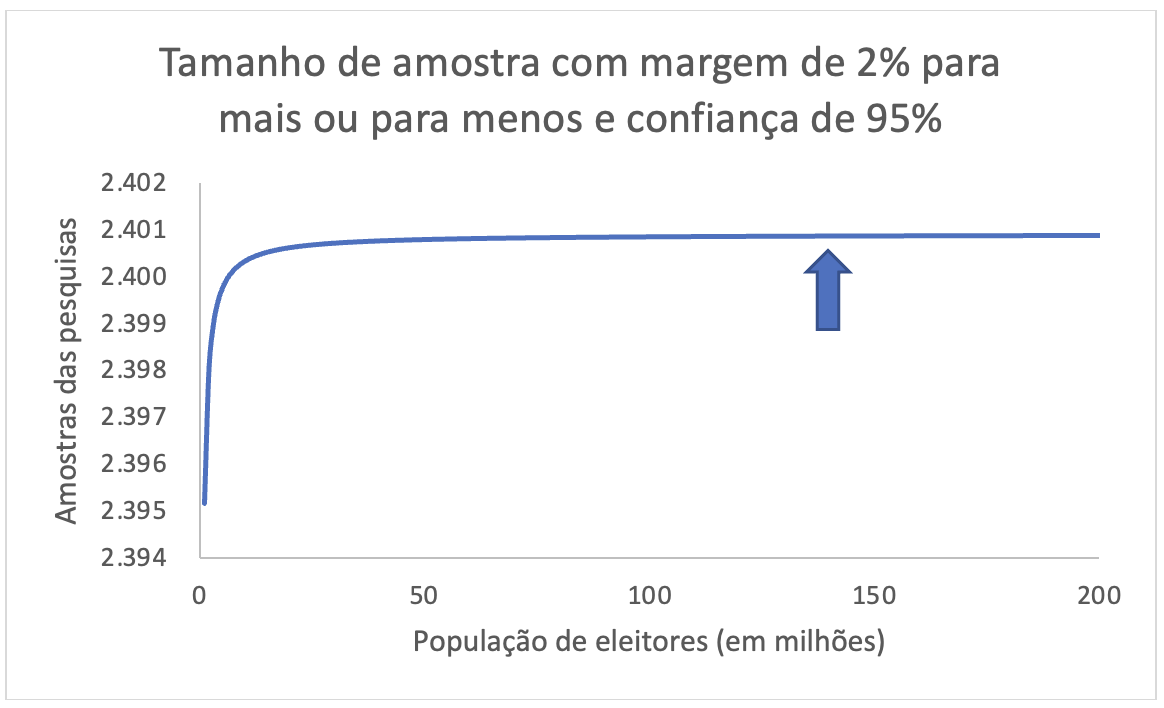
O que aconteceria se a população de um país variasse em até 200 milhões de eleitores? A partir de uma população de mais ou menos 14 milhões, bastaria uma amostra de 2401 pessoas, com amostragem probabilística, para representar todos os 14 milhões de eleitores, com uma margem de erro de 2% para mais ou para menos e confiança de 95%.
O Brasil tem algo em torno de 150 milhões de eleitores, mas se tivesse 50 milhões, 100 milhões ou 200 milhões, os mesmos 2401 eleitores seriam suficientes para representar toda a população.
Então como explicar tantas divergências entre os resultados das pesquisas?
Duas explicações são as mais simples para o eleitor ficar por dentro do que acontece.
A primeira é a metodologia utilizada por cada instituto. Vamos exemplificar como os dois institutos mais conhecidos da população realizam suas pesquisas. Por exemplo, o IPEC, que se originou a partir do extinto IBOPE Inteligência, utiliza a pesquisa presencial em domicílio como metodologia. Já o Datafolha, utiliza a pesquisa presencial em pontos de fluxo, que são pontos estratégicos para a coleta da informação e que não tem a ver com o local possuir uma grande circulação de pessoas.
Ou seja, a discrepância dos resultados já se justifica pelos institutos possuírem metodologias diferentes, com vieses distintos.
O viés do Datafolha foi maior, em relação ao percentual real de eleitores do Presidente Bolsonaro, muito provavelmente, porque a coleta de dados não investigou o eleitor motorizado e é sabido que o eleitor do Presidente Bolsonaro é majoritariamente das classes mais altas, fato que é realçado pelas suas “passeatas” serem motorizadas. Esse eleitor não está no ponto de fluxo de coleta do Datafolha. Isso levou ao instituto a subestimar o percentual real de eleitores do Presidente.
A segunda explicação é que a proporção de eleitores, ao longo das pesquisas, é medida pela intenção de voto que é uma variável aleatória. Ela não é um valor fixo. Muda a cada dia, de acordo com os cenários que os eleitores vão experenciando. Além de não captar o percentual de eleitores que vão revelar sua verdadeira intenção de voto na hora que digitam o número de seu candidato e apertam a tecla verde.
Enfim, cabe dizer que o percentual real só se conhece após a apuração dos votos, depois das eleições. Portanto, as movimentações finais só ficam conhecidas nas urnas. As pesquisas são retratos de um cenário que já faz parte do passado.
