
Fabiano Rodrigues
Vivemos em uma sociedade voraz na produção e consumo de dados, sejam eles no âmbito dos indivíduos ou das organizações. Dados de natureza diversificada, estruturados (como em uma planilha excel), semi-estruturados (arquivos json, por exemplo) e uma avalanche de dados não estruturados (como nas mídias sociais). Como extrair valor destes dados? Como encontrar padrões, realizar predições e fazer classificações?
O termo machine learning está em alta no mundo dos negócios, muitas promessas de aplicações para melhoria na tomada de decisão dos gestores. Mas, afinal, o que é machine learning?
Machine Learning (ML) é “o estudo de algoritmos de computador que melhoram automaticamente através da experiência” (ERTEL, 2017, p. 178). Similarmente, Facelli et al. (2019, p. 3) argumenta que em ML: “… computadores são programados para aprender com a experiência passada. Para tal, empregam um princípio de inferência denominado indução, no qual se obtém conclusões genéricas a partir de um conjunto particular de exemplos”. Assim, modelos de ML aprendem a induzir hipóteses ou funções que consigam resolver o problema (de regressão ou classificação) a partir do conjunto de dados.
A Figura 1 apresenta a lógica simplificada do processo de aprendizagem:
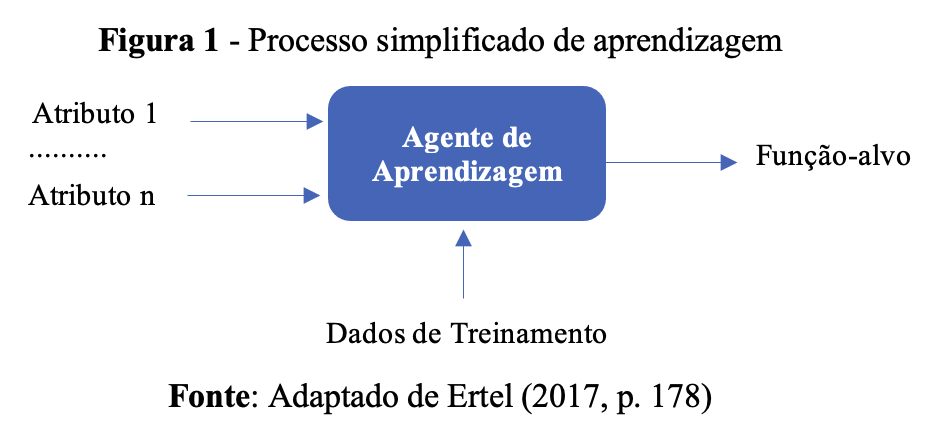
Um agente de aprendizagem é bem-sucedido se “melhorar seu desempenho (medido por um critério adequado) em dados novos e desconhecidos ao longo do tempo (após muitos exemplos de treinamento)” (ERTEL, 2017, p. 178). São necessários muitos exemplos iniciais de treinamento para que a predição tenha êxito.
As tarefas de aprendizagem podem ser divididas em duas macro categorias: aprendizado supervisionado e não supervisionado.
Na aprendizagem supervisionada, há a tentativa de predição de uma variável alvo a partir de um conjunto de atributos, por meio da classificação ou regressão. O termo supervisionado refere-se ao conhecimento inicial do estado da variável dependente do modelo para cada vetor de atributos dos exemplos contidos no conjunto de dados de treinamento, como se tivessem um “rótulo” para ajudar no processo de aprendizagem.
Já na aprendizagem não supervisionada, a predição cede espaço para a descrição, seja na forma de agrupamento, associação ou sumarização. Neste caso não existe um atributo-alvo à priori, busca-se padrões entre atributos ou objetos contidos no conjunto de dados.
Skiena (2017) argumenta que dificilmente um algoritmo de ML é superior a todos, pela diversidade de domínios, contexto do problema de decisão e da própria característica dos dados. A Tabela 1 mostra uma avaliação subjetiva, em uma escala de 1 (pior) a 10 (melhor), de algumas técnicas de ML em cinco dimensões: poder, facilidade de interpretação, facilidade de uso, velocidade de treinamento e velocidade de predição.
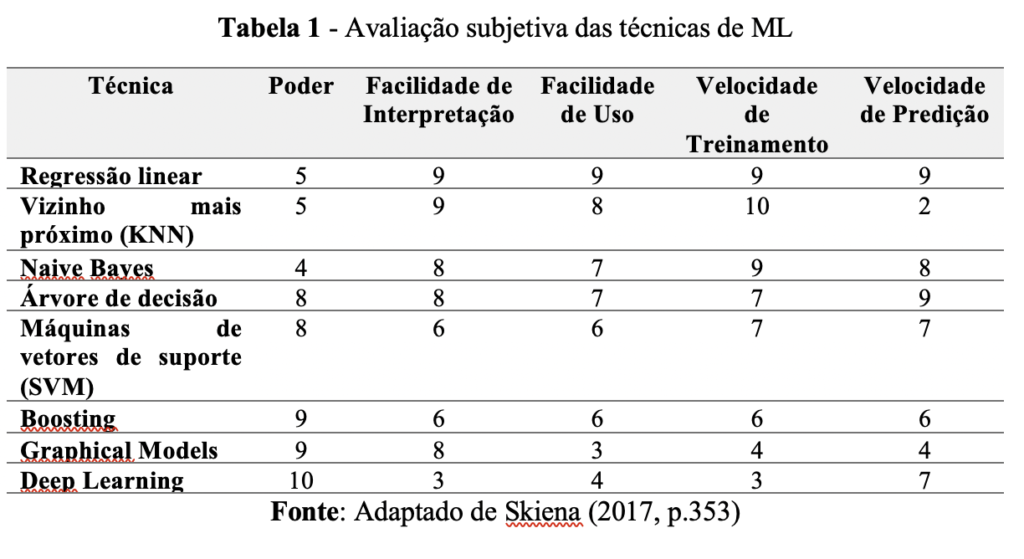
Há um trade-off natural entre as dimensões expostas na Tabela 1. Algumas técnicas geram maior facilidade para a interpretação dos resultados (por exemplo, Árvore de Decisão). Já outras, como Deep Learning, possuem alto poder de predição e baixa facilidade de interpretação, muitas vezes chamadas de black-box models.
Administradores, cada vez mais, precisam conhecer os conceitos e oportunidades advindas do uso de machine learning, até mais do que a programação em si dos algoritmos (mesmo que o domínio da programação, em Python por exemplo, seja uma competência útil). Administradores devem “enxergar” o uso de ML, seja na área de Marketing (clusterização de clientes), Vendas (previsão de novos pedidos a partir do perfil dos clientes), Finanças (perfil de crédito de clientes), entre outras. As aplicações são inúmeras, mas o uso efetivo de ML é potencializado com um olhar orientado para decisões de negócio.
REFERÊNCIAS
ERTEL, W. Introduction to Artificial Intelligence. 2nd ed. London: Springer, 2017.
FACELLI, K. et al. Inteligência Artificial: uma abordagem de aprendizado de máquina. Rio de Janeiro: LTC, 2019.
SKIENA, S. S. The Data Science Design Manual. Suiça: Springer, 2017.
